Large Language Models (LLMs) comes with built in knowledge and capable of Content Manipulation (creation, summarization, paraphrasing, translation, etc), Question Answering, Inferring Conclusions, Learning Patterns, etc. Prior to LLMs, all above tasks were only possible by intelligent humans. But LLMs have made it possible for super fast computers to carry out these actions with high accuracy.
Retrieval Augmented Generation
Retrieval Augmented Generation
Retrieval Augmented Generation [RAG] is a way to feed context-specific, accurate and timely external information to LLMs. When combine these two aspects (1. LLM capabilities and 1. knowledge specific to a domain/entity), many entities could develop solutions to cater their internal and external information needs at much efficient way compared to getting humans involved.
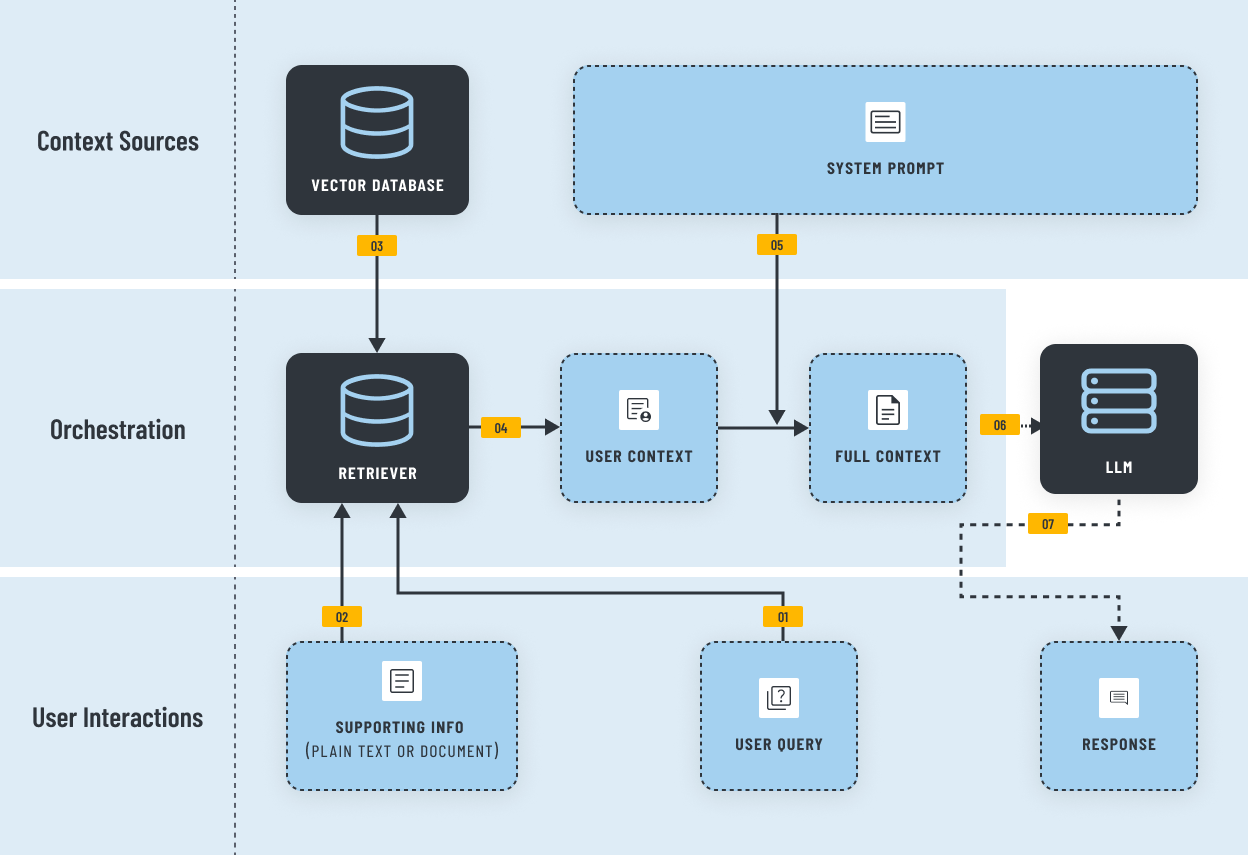
RAG Workflow
RAG Workflow
Why Businesses Need RAG Solutions Today
Why Businesses Need RAG Solutions Today

Internal Knowledge Assistants

Customer Support Automation

Policy/Document Search

Technical Troubleshooting Guides

Compliance And Auditing Support

Product Discovery & Recommendations
RAG related models & tools
RAG related models & tools
Embedding Models



Vector Databases




Rerankers



Eval Frameworks




LLM Models

Retrievers



LLM Orchestrators




RAG Services




LLM & RAG Options
LLM & RAG Options

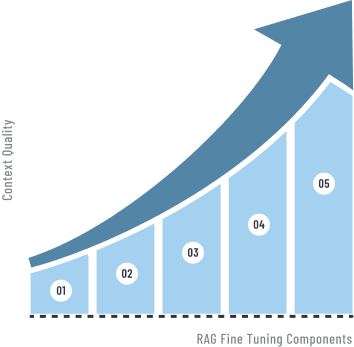
RAG Fine tuning
RAG Fine tuning
Enrich with domain specific knowledge. Create sub queries, Prompt step-back questions
Supplement vector similarity search with Knowledge Graphs, Keyword Searches etc
Dynamically switching paths within the RAG pipeline to use agents, tools, and any other transformers for the specific user query
Query
Indexing
Retriever
Generator
Rag Pipeline
Optimizing the creation of chunking indexes using techniques such as multi-chunking, step-wise indexing, or multi-way indexing
Adjusting and optimizing query and context to LLM friendly. Break down the task to sub tasks
1
Query
2
Indexing
3
Retriever
4
Generator
5
Rag Pipeline
Probabilistic vs Deterministic
Probabilistic vs Deterministic
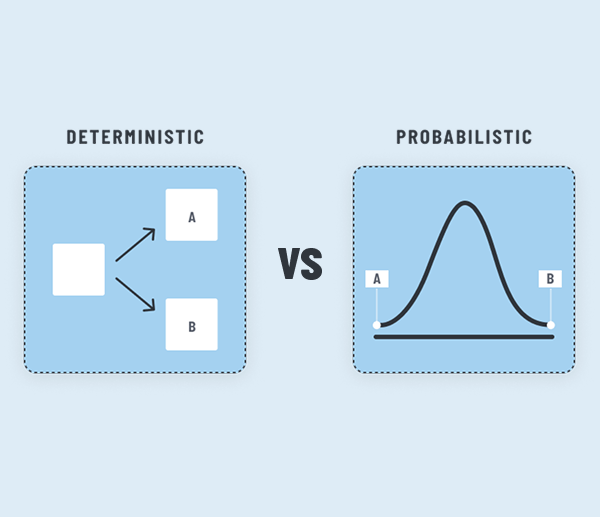
Software systems are usually deterministic, meaning, for a given set of inputs, they always produce same set of outputs. This is what we are used to but when we use LLMs, certain parts of the solution become probabilistic. Meaning, it will not always produce the same set of outputs for a given set of inputs. This introduces a great number of difficulties when developing solutions using LLMs.
This uncertainty even could lead to unprecedented project failures. A PoC and an MVP which gave promising results could miserably fail in a production setup. So it is important to understand this complexity and deal with it in a pragmatic way from the initial stage of the solution development. And this found to be a common pitfall for many RAG solutions.
This uncertainty even could lead to unprecedented project failures. A PoC and an MVP which gave promising results could miserably fail in a production setup. So it is important to understand this complexity and deal with it in a pragmatic way from the initial stage of the solution development. And this found to be a common pitfall for many RAG solutions.
Our Approach
Our Approach
Full Traceability
Extensive message and information logging is a key apart of our RAG solution design. It enable both end user and developers equally to use and improve the system.
Continuous Quality Checks
Due to the probabilistic nature of LLMs it is important to built in evaluation processes to the system even on production stage. We build these features into the system from the beginning.
Edge Cases
Knowing where solution fail or will produce responses which are not acceptable is a key measurement. We spend time to identify what are the edge cases and make sure to establish necessary guardrails.





FIDENZ APPROACH
Limitations of LLMs and RAGs
LLMs could easily surprise you with exceptional results. But such results could easily fade off with time. So it is vital to know limitations of LLMs and design the systems under those conditions.
Living Organism
We treat a RAG based solution as a“living organism” rather than a traditional “build and ship” type solutions. Accuracy of the system could change due to so many factors so we take care of the system by grooming and nurturing it over time.
Deterministic vs. Probabilistic
Our approach is to use deterministic options as much as possible, and use probabilistic options only when necessary when building solutions. This help us to define and guarantee the system capabilities in a more predictable manner.
Limitations of LLMs and RAGs
Living Organism
Deterministic vs. Probabilistic
Edge Cases
Continuous Quality Checks
Full Traceability